
Neith
versión Beta

11. ANEXO 2 - REGLA combo_rule
REGLA PARA LA SELECCIÓN MEJOR COMBINACIÓN DE MODELOS ESTRATEGIA 3
1) single_top1 — usar sólo el mejor modelo
-
Cuándo: cuando la lógica del Paso 5 decide no mezclar (p. ej., porque top-1 es claramente dominante o no hay top-2 válido).
-
Qué hace: toma directamente el modelo_top1 elegido en la selección previa (top-1 por MASE12).
-
Dónde se justifica/documenta: la Estrategia 3 trabaja con top-2 por serie y puede optar por no combinar (modelo único) según la calidad/condiciones. Esto se describe en el flujo de Estrategia 3 (selección y ensembles) y en la memoria (pasos 4–6).
2) mean50_50 — promedio simple de top-1 y top-2
-
Cuándo: cuando no hay información fiable para ponderar por calidad (o como fallback de la ponderación por error).
-
Qué hace: calcula
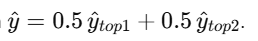
-
Dónde está en el código: en la rama de INTERMITENTE (TSB + ADIDA/MAPA), si no se dispone de MASEs válidos se cae a promedio 50/50.
-
Contexto: el cuaderno describe el Paso 5 como “ensembles y predicción 2024” combinando los top-2.
3) weighted_by_inv_MASE12 — promedio ponderado por 1/MASE12
-
Cuándo: cuando hay métricas MASE12 por modelo disponibles (derivadas de la validación rolling) para esa pareja.
-
Qué hace: si existen MASE12 válidos de ambos modelos, se pesa cada uno con el inverso de su error (más peso al que
menos error tiene):
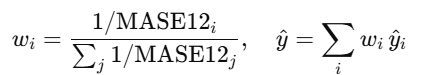
-
Dónde está en el código: mismo bloque de INTERMITENTE (TSB + ADIDA/MAPA); si hay MASEs válidos, se usa la ponderación por 1/MASE12.
-
Contexto: el cuaderno y la memoria señalan que el Paso 5 re-entrena con todo 2021–2023 y combina top-2 con reglas simples o ponderadas, coherentes con la filosofía “champion–challenger”.
4) Fallbacks — fallback_snaive12 / baseline_cero
- Cuándo:
-
Por reglas del Paso 5 si un entrenamiento falla/insuficiente, o si la serie es de cero estructural.
-
Por gobernanza del Paso 6 si el top-1 no supera a SNaive12 en 2024 se fuerza SNaive12.
- Qué hacen:
-
baseline_cero: predicción 0 para series con cero estructural (train todo en cero) y monitorización de “cero→actividad”.
-
fallback_snaive12 (en el CSV puede verse como fallback_snaive12_cv): usar SNaive12 cuando el candidato falla o no mejora.
- Dónde se ve:
-
Logs y notas del cuaderno con listados extensos de “baseline_cero registrado” (bandera flag_all_zero_train=1).
- Justificación y pasos de gobernanza comparando contra SNaive12 en 2024 (regla de reemplazo).
5) Referencias:
https://www.datarobot.com/blog/introducing-mlops-champion-challenger-models/
https://robjhyndman.com/nyc2018/1-3-ForecastEvaluation.pdf
https://otexts.com/fpp3/combinations.html
https://robjhyndman.com/publications/combinations/
https://stats.stackexchange.com/questions/163074/assigning-weights-to-an-averaged-forecast