

5. SOLUCIÓN PLANTEADA
La solución diseñada para abordar el problema de previsión de gasto en FerMar S.L. se apoya en dos pilares complementarios:
- Ciencia de Datos y Backoffice:
En primer lugar, se ha desarrollado un flujo metodológico sólido basado en técnicas de Data Science, centrado en series temporales y modelos híbridos. Este flujo incluye limpieza, validación, selección de modelos bajo un esquema champion–challenger y gobernanza mediante métricas como el WAPE. Todo ello se articula como un proceso robusto de backoffice, invisible al usuario final pero esencial para asegurar la calidad y trazabilidad de las predicciones.
- Tecnología Web y Experiencia de Usuario:
En paralelo, la solución incorpora un servicio web desplegado en un entorno AWS, bajo el dominio fmpredict.com. Este entorno tiene un doble propósito:
- Documentación y explicación del proyecto: facilita la comprensión de la metodología aplicada y de las decisiones tomadas.
- Entorno visual de interacción: permite a los responsables de Facility Management visualizar las previsiones generadas y, de forma periódica, cargar la realidad ejecutada. De este modo, la plataforma actúa como puente entre el backoffice de ciencia de datos y la toma de decisiones diaria en la organización.
La combinación de ambos enfoques —un motor predictivo robusto en backoffice y una interfaz web intuitiva en AWS— asegura que el sistema no solo genere previsiones más precisas, sino que también sea accesible, usable y sostenible para el cliente en su operativa habitual.
-
Metodología En Ciencia De Datos
La metodología utilizada es iterativa, pragmática y evolutiva, siguiendo un enfoque de "champion–challenger" justificado por la inestabilidad de los datos. Se estructuró en tres estrategias secuenciales:
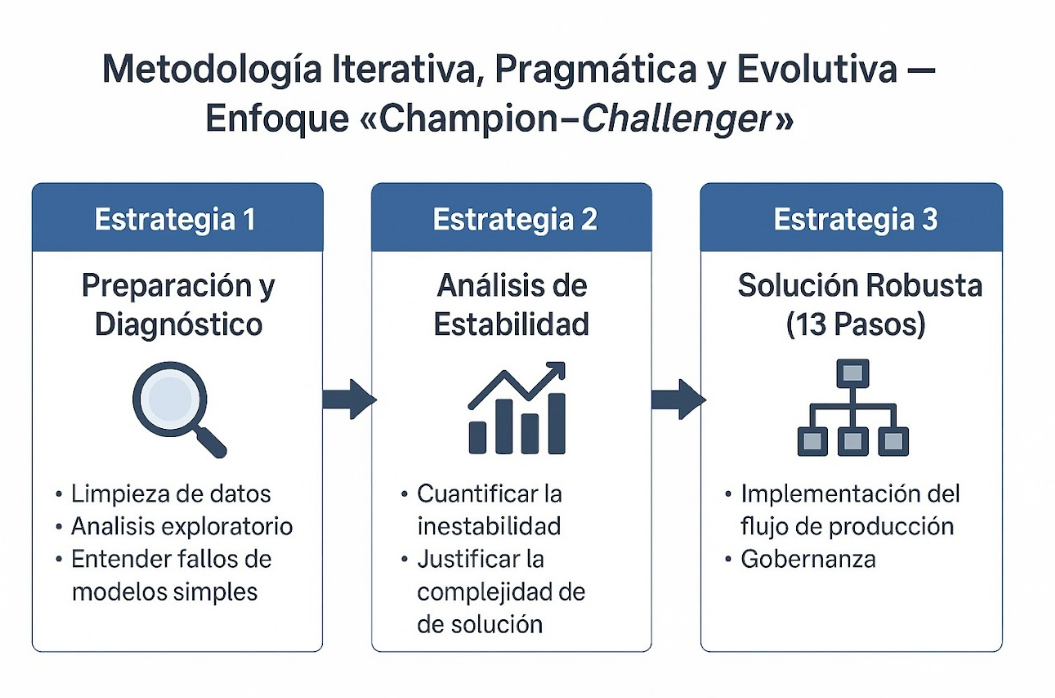
Estrategia 1 (Preparación y Diagnóstico): Enfocada en la limpieza y el entendimiento profundo de la naturaleza de las series tras el fallo de los modelos simples.
Estrategia 2 (Análisis de Estabilidad): Cuantificación de la inestabilidad para justificar la complejidad de la solución final.
Estrategia 3 (Solución Robusta - 13 Pasos): Implementación del flujo de producción y gobernanza.
-
Desarrollo De Cada Etapa
- Estrategia 1: Análisis Exploratorio, Piloto Fallido y primer diagnóstico
Propósitos:
- Asegurar la calidad y consistencia del dataset inicial (FD1) antes de aplicar cualquier modelización.
- Entender la naturaleza de las series (tendencias, estacionalidad, errores de codificación, categorías con ruido)
- Establecer un diagnóstico base que justifique por qué los modelos simples (naive, media histórica) no eran suficientes.
Fase de Preparación: Se trabajó con el histórico de gasto FM (2021-2025). Se realizó AED y se colaboró con el equipo de FM de FerMar S.L. para corregir anomalías, reclasificar variables (ID_BUSINESS_UNIT_MOD), y eliminar registros fuera de perímetro (Marruecos/Italia, CAPEX, clases minoritarias de FM_RESPONSIBLE). Esto condujo al dataset df_fd1_v5.
- Carga y exploración inicial del dataset (FD1):
- Fuente: histórico de contrataciones de servicios y mantenimientos (324.439 registros, 15 columnas).
- Variables clave: COST, COST_TYPE, SUPPLIER_TYPE, COUNTRY, FM_COST_TYPE, YEAR_MONTH.
- Conversión y tratamiento de campos:
- COST venía como texto → se creó cost_float.
- Se detectaron 47 registros con error tipo #DIV/0! (todos en Marruecos, suministro eléctrico). Se decidió eliminarlos porque además Marruecos quedaba fuera de alcance.
- Corrección de categorías mal codificadas:
- En SUPPLIER_TYPE había valores 0. Se consultó con FM y se reasignaron manualmente a “EXTERNO” mediante diccionario.
- Homogeneización de valores categóricos:
- En FM_COST_TYPE se detectó el valor “Vacío” que debería ser NaN → estandarización.
- Análisis exploratorio (EDA):
- Distribución de costes por país, año y tipo de coste.
- Identificación de anomalías (outliers de gasto, meses con desviaciones).
- Confirmación de que la serie es inestable e irregular a nivel inmueble, aunque se compensa cuando se agrupa por cuentas o países.
- Criterios de exclusión y segmentación:
- Italia y Marruecos quedaron fuera por decisión del cliente.
- Se prepararon catálogos y diccionarios para anonimizar y estructurar los IDs de proveedores, inmuebles y contratos.
- Revisión con el área de Facility Management:
- Validación de las transformaciones.
- Confirmación de que FD1 es la única fuente utilizable en la Fase 1, ya que FD2 y FD3 no estaban disponibles.
- Confirmamos las parejas o pares a predecir: ID_BUILDING, FM_COST_TYPE en dos series de datos históricos, el ITE1 relativo al histórico de gastos de los años 2021 a 2023 con un dataset real de 2024 completo, y el ITE2 relativo al histórico de gastos de los años 2022 a 2024 con un dataset real de 2025 hasta agosto.
Diagnóstico de Comportamiento y priimeras estimaciones: Se calculó un Mapa de Diagnósis para 2.429 parejas (ID_BUILDING, FM_COST_TYPE), calculando KPIs como la fuerza estacional (seasonal_strength_stl), max_zero_run y tendencia. El resultado de la validación inicial fue que los modelos sugeridos (ETS, ARIMA,...) "no baten al naive estacional de media".
- Después de depurar el dataset FD1, se evaluó cómo se comportaban las series de gasto a nivel inmueble y tipo de coste.
- Para ello, se construyó un Mapa de Diagnóstico con 2.429 parejas (ID_BUILDING, FM_COST_TYPE) y se calcularon KPIs específicos de series temporales:
- Fuerza estacional (seasonal_strength_stl): obtenida con descomposición STL, mide qué parte de la variabilidad de la serie se explica por un patrón estacional.
- Tendencia: componente extraída también de STL, para identificar inmuebles con dinámica creciente o decreciente.
- Max_zero_run: longitud máxima de rachas con valor 0, indicador de intermitencia típica en contratos o consumos que no aparecen cada mes.
Con estas métricas se clasificaron las series en segmentos (estables, intermitentes, dominadas por estacionalidad, dominadas por ruido, etc.), lo que permitió entender mejor la naturaleza del problema.
Resultado del diagnóstico
- Al aplicar estos modelos clásicos (ETS, ARIMA y derivados) sobre las series según el diagnóstico realizado a través de KPIs, se observó que no superaban en precisión al modelo naïve estacional (SNaive12), que simplemente replica el valor de hace 12 meses como predicción.
- Es decir, en términos de métricas de error, la complejidad adicional de ETS o ARIMA no aportaba mejora significativa frente al baseline estacional.
- Esto nos confirmó que la variabilidad inmueble por inmueble es muy alta, y que sin tratamiento adicional de inestabilidad o reconciliación, los modelos sofisticados no son mejores que una simple regla de repetición.
Conclusión
- Esta validación inicial puso de manifiesto que el problema no era solo de escoger “un mejor modelo”, sino de abordar la inestabilidad estructural de las series. Este hallazgo justificó dar el salto a la Estrategia 2 (Análisis de Inestabilidad).
- Estrategia 2: Análisis Serie por Serie y Detección de Cambio Estructural
Propósitos
- Validar la estabilidad temporal de cada serie y clasificarla según su comportamiento, con el fin de anticipar si los modelos estadísticos simples podrían ofrecer resultados fiables o si era necesario diseñar un flujo más complejo.
Procedimiento aplicado
- Detección y tratamiento de outliers
Se identificaron valores atípicos extremos en las series de gasto, especialmente en contratos con picos puntuales de coste.
Para robustecer el análisis, se generaron dos versiones depuradas de la variable de gasto:
- cost_float_mod_2 → tratamiento conservador, suavizando outliers sin alterar demasiado la serie.
- cost_float_mod_3 → tratamiento más agresivo, eliminando o corrigiendo valores que distorsionaban la tendencia.
El propósito fue comprobar cómo y cuánto la estabilidad y el ajuste de los modelos se veían afectados según el nivel de corrección aplicado.
- Evaluación de cambio estructural
Se diseñó un test comparativo train vs. test para cada pareja (ID_BUILDING, FM_COST_TYPE).
Se midieron cambios bruscos de performance, es decir, diferencias significativas en error al pasar de entrenar con histórico a validar en periodo reciente.
Con este criterio se clasificaron las series en dos grupos:
- Series Estables: mantienen un comportamiento similar entre train y test.
- Series con cambio estructural: presentan saltos, rupturas o dinámicas distintas que impiden confiar en la extrapolación de modelos clásicos.
- Mapa de estabilidad
Se construyó un resumen visual para representar el grado de estabilidad de las series según los KPIs analizados.
Este mapa permitió cuantificar el tamaño del problema: la mayoría de las series tenían algún nivel de inestabilidad.
Resultados y hallazgos
Solo entre el 15% y el 18% de las series podían considerarse estructuralmente estables.
En el resto, los cambios de comportamiento eran demasiado significativos, lo que implicaba que los modelos estadísticos clásicos (ETS, ARIMA, Holt, etc.) no eran suficientes.
Este hallazgo reforzó la necesidad de un enfoque evolutivo y más robusto, capaz de:
- manejar intermitencia,
- reconciliar resultados a nivel agregado,
- adaptarse a la inestabilidad estructural.
Conclusión
La Estrategia 2 confirmó que la complejidad del problema no residía únicamente en la precisión de los modelos, sino en la inestabilidad intrínseca de las series de gasto.
Durante esta etapa se verificó además que la elección de la iteración de validación (ITE1 frente a ITE2) no producía diferencias significativas en los resultados obtenidos, manteniéndose estables las métricas globales y la clasificación de las series entre ambos escenarios. De igual forma, el tratamiento de outliers mediante aplanamiento —tanto en su versión conservadora (cost_float_mod_2) como en la más agresiva (cost_float_mod_3)— tampoco modificaba de manera sustancial las conclusiones alcanzadas.
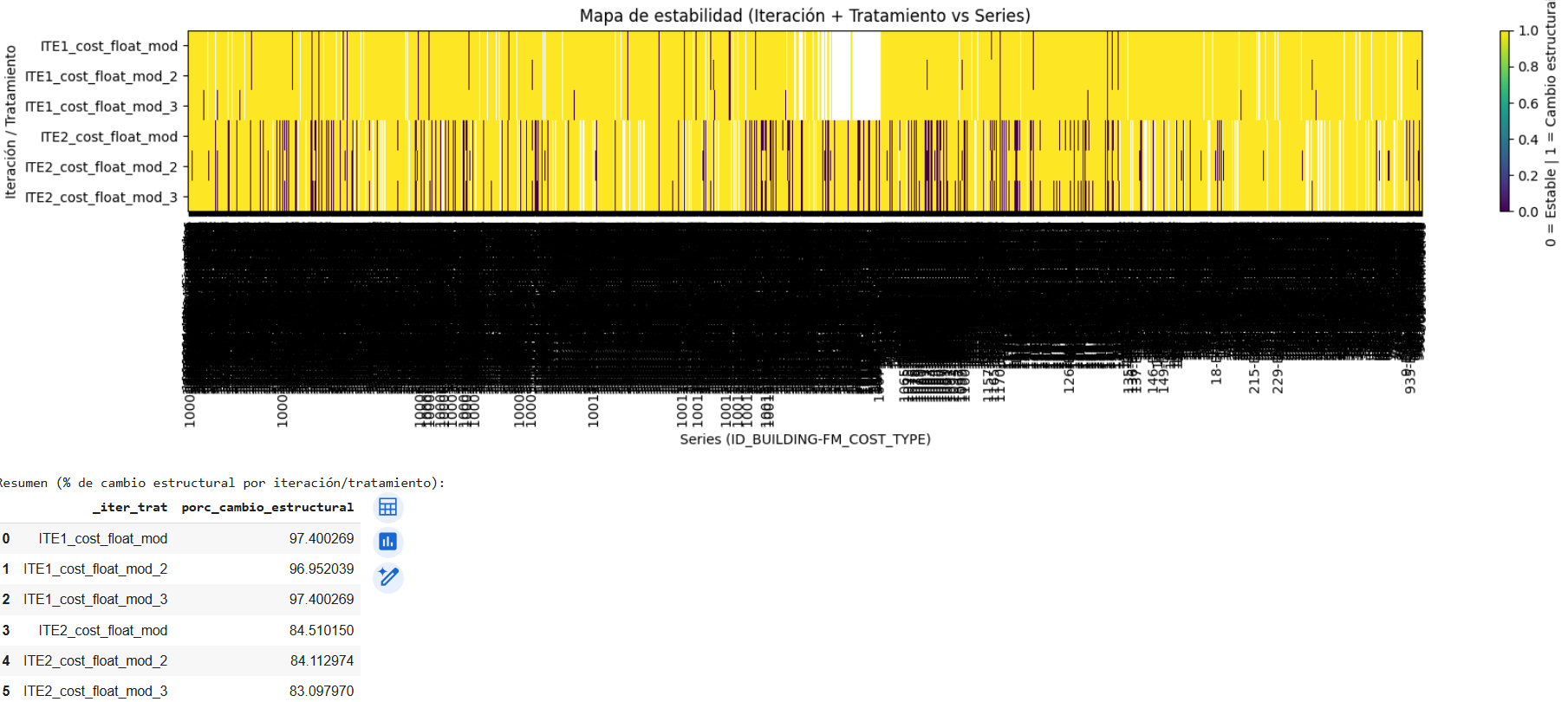
Estos hallazgos permitieron confirmar que la baja proporción de series estructuralmente estables (15–18%) no era atribuible ni a la configuración de iteración ni a la presencia de valores atípicos, sino que respondía a cambios estructurales profundos en el comportamiento de las series, reforzando así la necesidad de evolucionar hacia la Estrategia 3.
Por tanto, se justificó la necesidad de la Estrategia 3, que integró técnicas de reconciliación, champion–challenger y gobernanza de predicciones para obtener una solución robusta.
- Estrategia 3: Solución Robusta y Flujo de Producción con lógica champion-challenger
En primer lugar, se calcularon los modelos de referencia o baselines (Paso 1) que sirven para fijar el champion, concretamente Naive(1), SNaive(12) y la Mediana Estacional. Su función era establecer un suelo mínimo de rendimiento contra el que cualquier modelo candidato debía ser comparado. El candidato elegido fue SNaive(12).
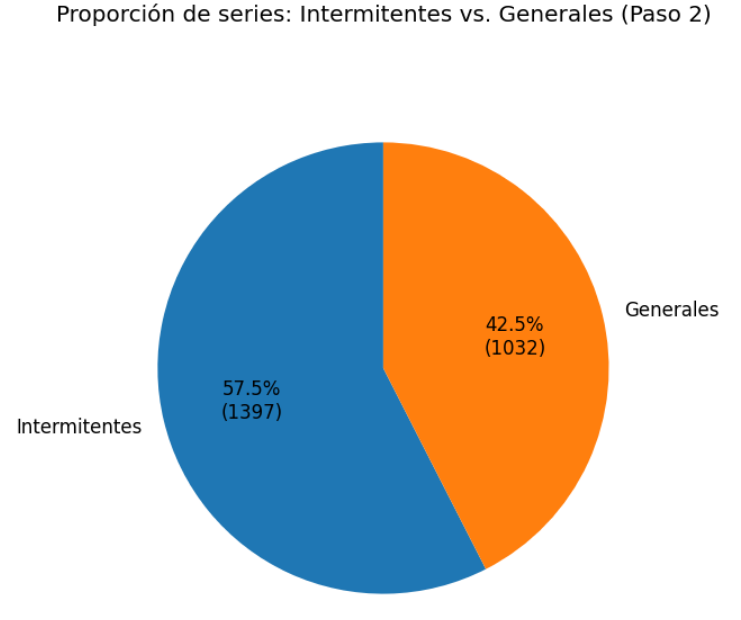
A partir de ahí se llevó a cabo una segmentación dual de las series (Paso 2), distinguiendo entre intermitentes y generales. Esta clasificación se realizó mediante la métrica de rachas máximas de ceros, determinándose que el 57,5 % de las series eran intermitentes y debían abordarse con modelos especializados como Croston, TSB o ADIDA, mientras que el 42,5 % restante se trató con algoritmos de tipo ETS, ARIMA o Theta.
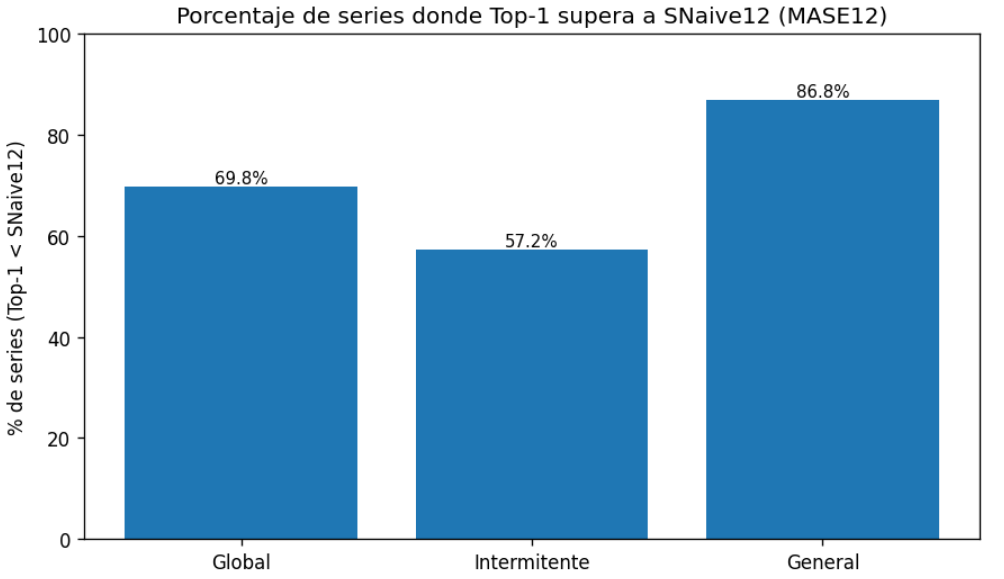
Sobre esa base se definieron menús de modelos especializados para cada segmento (Paso 3), reduciendo ruido y asegurando que cada serie recibiera un conjunto de candidatos coherente con su naturaleza. Posteriormente se aplicó la validación con rolling origin (Paso 4) sobre ventanas móviles de la serie ITE1, año 2021 a 2023, utilizando el MASE12 como criterio prioritario. Esta validación permitió identificar el Top1 y Top-2 de modelos por serie y comprobamos que el Top-1 lograba superar al SNaive12 en cerca del 70% de los casos. Es decir, asignando entrenamientos en varias ventanas temporales distintas fijando el mismo origen nos permitió elegir el mejor de los modelos ganador de varias series. No nos quedamos solo con un primer mejor modelo (estrategia 2) sino que nos quedamos con el mejor primero y el mejor segundo de entre varios entrenamientos.
Con los candidatos seleccionados se procedió al reentrenamiento con todo el histórico 2021–2023 y a la combinación del Top1 y Top-2 mediante reglas 50/50 o ponderadas (Paso 5), generando así las previsiones completas para el año 2024. Este mecanismo se complementó con la existencia de fallbacks hacia SNaive12 o incluso hacia el baseline_cero en caso de que una serie no pudiera ser cubierta por modelos más complejos, garantizando así la cobertura total del universo de series.

La distribución final nos confirmó el papel central del ensemble Top-2, que concentró el 65 % de las series, convirtiéndose en la solución más robusta y generalizable del pipeline. No obstante, casi un tercio de las series requirieron el fallback SNaive12, lo que demuestra que, pese a la complejidad añadida, la inestabilidad estructural de los datos siguió obligando a apoyarse en este baseline como red de seguridad. El baseline_cero, aplicado en un 4 % de los casos, refleja aquellas series con señal insuficiente para modelizar. La ausencia de resultados en Top-1 en solitario muestra que el proceso de gobernanza y combinación estaba diseñado para priorizar siempre la robustez: o bien reforzando con un Top-2, o bien garantizando cobertura con fallback. En conjunto, la estrategia definida y la regla combo (ver detalle en Anexo 2) lograron un equilibrio entre sofisticación y fiabilidad, asegurando que ninguna serie quedara sin previsión.
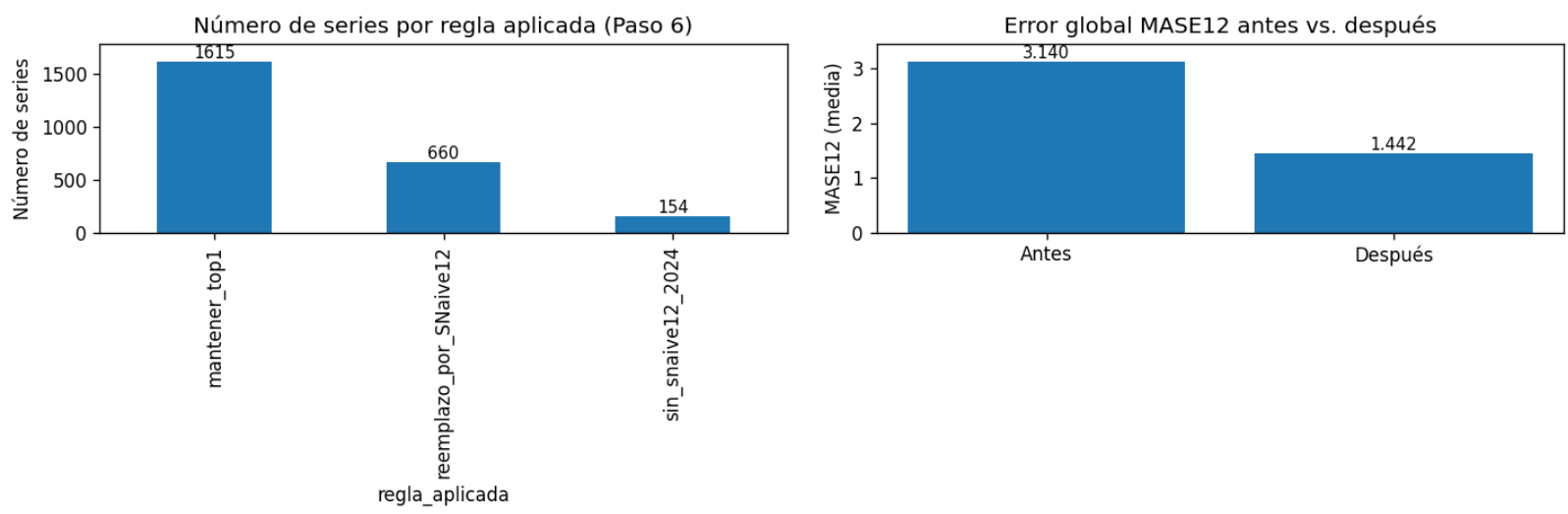
A continuación se introdujeron reglas de gobernanza de resultados (Paso 6). El criterio fundamental fue que el modelo final debía superar siempre al baseline SNaive12. Esta regla forzó 660 reemplazos automáticos, que fueron validados posteriormente en un proceso de revisión (Paso 7), confirmando que el efecto neto era una mejora en la calidad global de las predicciones y una mayor homogeneidad en su comportamiento. Una vez asegurada esta gobernanza, los resultados se consolidaron en outputs uniformes por pareja (Paso 8), generando las versiones preds_base_2024 y las ajustadas por política, de modo que se eliminaron inconsistencias y se facilitó el paso a las fases de reconciliación. El aseguramiento de cobertura se reforzó con un proceso adicional (Paso 9) en el que se aplicaron fallbacks en aquellas series problemáticas, evitando huecos en la entrega final.
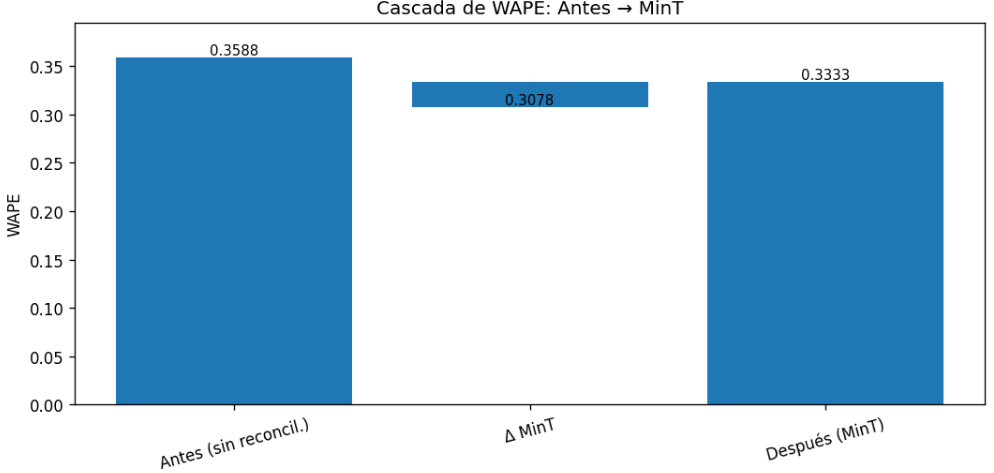
Una vez completado este aseguramiento se procedió a la reconciliación jerárquica (Paso 10) para garantizar la coherencia entre los distintos niveles de agregación. Para ello se implementó el método MinT shrink en una lógica bottom-up, que permitió imponer consistencia aritmética entre series individuales, países y consolidado global (ver anexo 3). La reconciliación fue objeto de una validación específica (Paso 11) que comparó métricas como WAPE, SMAPE y MASE antes y después de su aplicación. El resultado fue que la coherencia se alcanzaba sin un deterioro excesivo en la precisión individual de las predicciones.
No obstante, se decidió que la versión de producción activa debía alinearse con los criterios de negocio. Por ello se introdujo un anclaje basado en el Real 2023 escalado por IPC (Paso 12), asegurando la consistencia estructural de las cifras a pesar de mostrar métricas ligeramente peores que la reconciliación MinT pura.
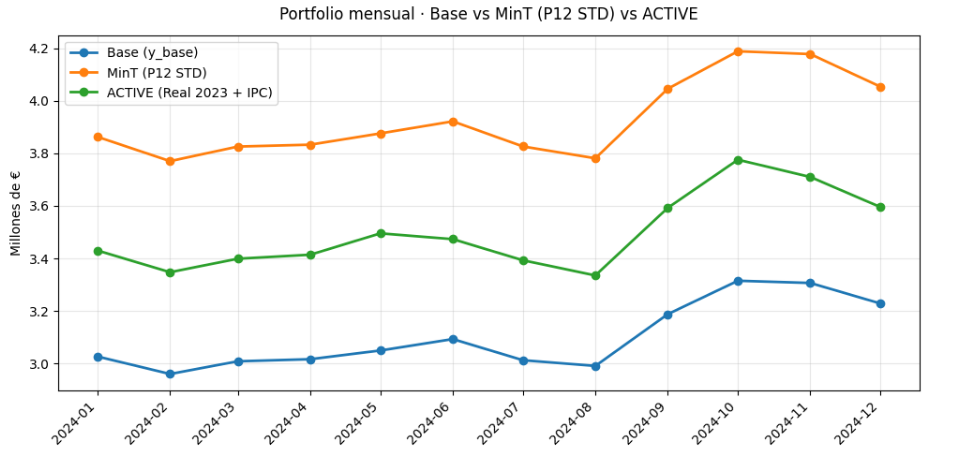
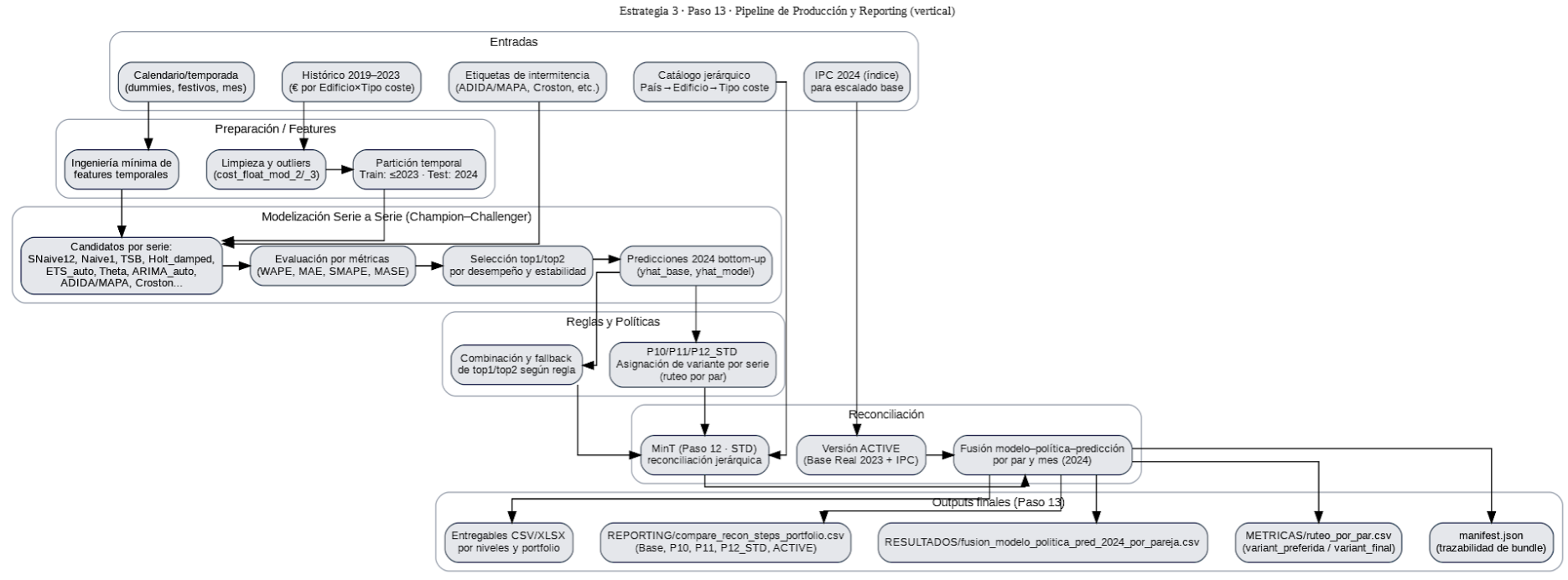
Finalmente, el proceso culminó con la entrega y gobernanza final (Paso 13). Se preparó un paquete de resultados que incluía las previsiones reconciliadas (fusion_modelo_politica_pred_2024_por_pareja.csv), métricas de validación y un fichero de manifiesto (manifest.json) que recogía la trazabilidad completa de las políticas aplicadas, incluyendo P10, P11 y P12. Este cierre permitió disponer de un producto auditable y transparente, con una hoja de ruta clara para la evolución futura del sistema de previsión.
El flujo siguiente resume los pasos seguidos y los artefactos obtenidos que son base para la funcionalidad de la aplicación web en su primer entregable (1ª iteración).
En conclusión, la Estrategia 3 permitió mejorar el WAPE global respecto a las estrategias anteriores, asegurar cobertura completa mediante fallbacks, aplicar una gobernanza estricta sobre la elección de modelos y consolidar un proceso productivo robusto y trazable. Este resultado justificó la complejidad del enfoque implementado y dio respuesta a la inestabilidad estructural detectada en las fases iniciales del proyecto.
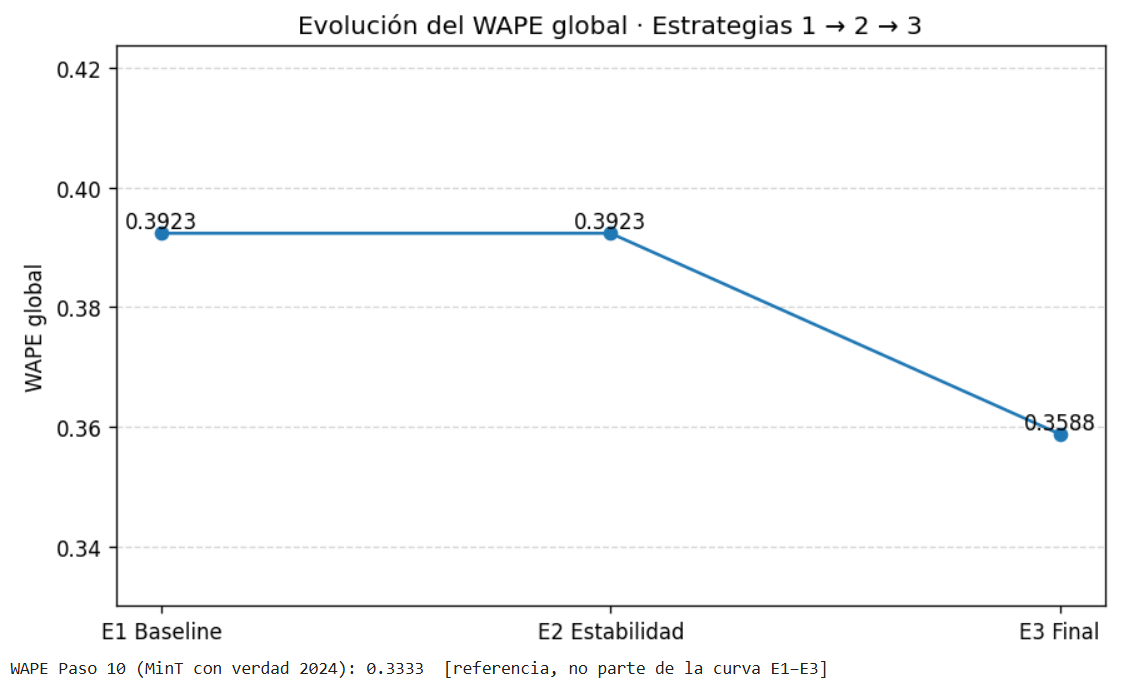
La curva que se obtuvo resume de manera clara la evolución del WAPE global a lo largo de las tres estrategias:
-
Estrategia 1 (Baseline, SNaive12):
-
Punto de partida con un WAPE global de 0.3923.
- Sirve como referencia para medir el valor añadido de las siguientes fases.
-
Estrategia 2 (Estabilidad):
-
El WAPE se mantiene en 0.3923, es decir, no hay mejora cuantitativa frente al baseline.
-
Sin embargo, esta fase no buscaba optimizar el error, sino validar la inestabilidad de las series y confirmar que los modelos simples no eran suficientes.
- La utilidad principal aquí fue diagnóstica, no de reducción de error.
-
Estrategia 3 (Modelo final):
-
El WAPE baja a 0.3588, lo que representa una mejora relativa de ~8.5 % frente al baseline.
El Paso 10 (MinT con verdad 2024), que no aparece en la línea porque es un ejercicio offline, mostró un WAPE aún menor (0.3333). Eso confirma que la reconciliación funciona muy bien con acceso a la realidad, aunque en producción el resultado consolidado fue el 0.3588.
- Aquí sí entra en juego el flujo completo: segmentación, champion–challenger, gobernanza y reconciliación.
- Es la demostración de que el enfoque robusto aporta valor tangible.
-
Inteligencia Artificial y Plataforma WEB
La capa web es el puente entre el modelo IA de predicción (backoffice) y la operación diaria del equipo de FM. Su objetivo es generar y justificar previsiones de forma transparente, trazable y reutilizable. Nosotros, en esta entrega, hemos realizado una demo para el cliente.
La simulación para la demo se encuentra en FerMar Predict (https://fmpredict.com) en donde la página WEB emulará estar en 2023 generando previsiones para 2024. Cargamos en la WEB los datos de entrada de FerMar Predict desde MongoDB, así como las predicciones 2024 ya obtenidas desde PostgreSQL, de modo que la experiencia del usuario sea idéntica a la que tendrán en producción.
- Beneficio para el propósito del proyecto
-
Decisión operativa con trazabilidad: cada cifra expuesta explica su porqué (variante, regla, disponibilidad, desempeño).
- Sostenibilidad y escalabilidad: los artefactos del Paso 13 separan motor y presentación, permitiendo renovar paquetes sin tocar la web en favor de la escalabilidad.
-
Cierre del ciclo OPEX: previsión → ejecución → métrica → aprendizaje, todo en el mismo entorno.
- Alineamiento negocio–modelo: ruteo por país/tipo, IPC y dimensiones integradas para hablar “el idioma” de FM.
- Arquitectura Full Stack
Para la generación de un MVP que funcione a la brevedad como demo y en el futuro como plataforma de producción, se requiere de la máxima escalabilidad y las mejores tecnologías disponibles en el mercado.
Nuestra percepción, basada en una investigación exhaustiva, de una arquitectura y desarrollo de una solución empresarial orientada a la integración de inteligencia artificial en flujos de trabajo reales fue utilizar un enfoque full stack con múltiples tecnologías.
Conocimos de antemano que la fuente principal de datos es una instancia externa de MongoDB (desde donde se obtienen los documentos para su análisis) con cientos de miles de documentos, lo cual definió en parte el reto y dimensión del requerimiento del cliente. La solución, por consiguiente, debe ser robusta y ágil, por lo que nuestras decisiones y selecciones en tecnología de software derivaron en lo siguiente:
Para el entrenamiento y evaluación de modelos de machine learning se utilizó una combinación de Google Colab, Jupyter Notebooks y Python, desarrollando la lógica algorítmica y los pipelines de procesamiento en un entorno controlado previo a su despliegue. El sistema completo se construyó integrando diversas herramientas: FastAPI como microservicio en Python para la capa del Backoffice y Ruby on Rails como framework para el frontend, así como para el backend de la página WEB; ambos entornos enfocados en la lógica de negocios y la persistencia estructurada.
Todo el ecosistema se encuentra orquestado sobre una instancia EC2 de Amazon Web Services (AWS), asegurado mediante TLS con certificados SSL (HTTPS) y servido por NGINX configurado para enrutar las solicitudes adecuadamente entre los distintos servicios. PostgreSQL es utilizado como base de datos transaccional en la capa Rails, mientras que Uvicorn y Puma se encargan de levantar los servidores correspondientes para FastAPI y Rails respectivamente. Se implementaron prácticas de seguridad de red con grupos de seguridad de AWS, y se consideró el uso de UFW para el firewall a nivel de sistema operativo. El control de versiones y la colaboración en el código se realizaron a través de GitHub. Esta arquitectura no sólo garantiza escalabilidad y seguridad, sino que permite una clara separación de responsabilidades entre la capa de presentación, los servicios de procesamiento y la lógica de negocio. Para minimizar la complejidad de lo expuesto anteriormente en esta sección, nuestra arquitectura full stack se demuestra en el siguiente esquema:
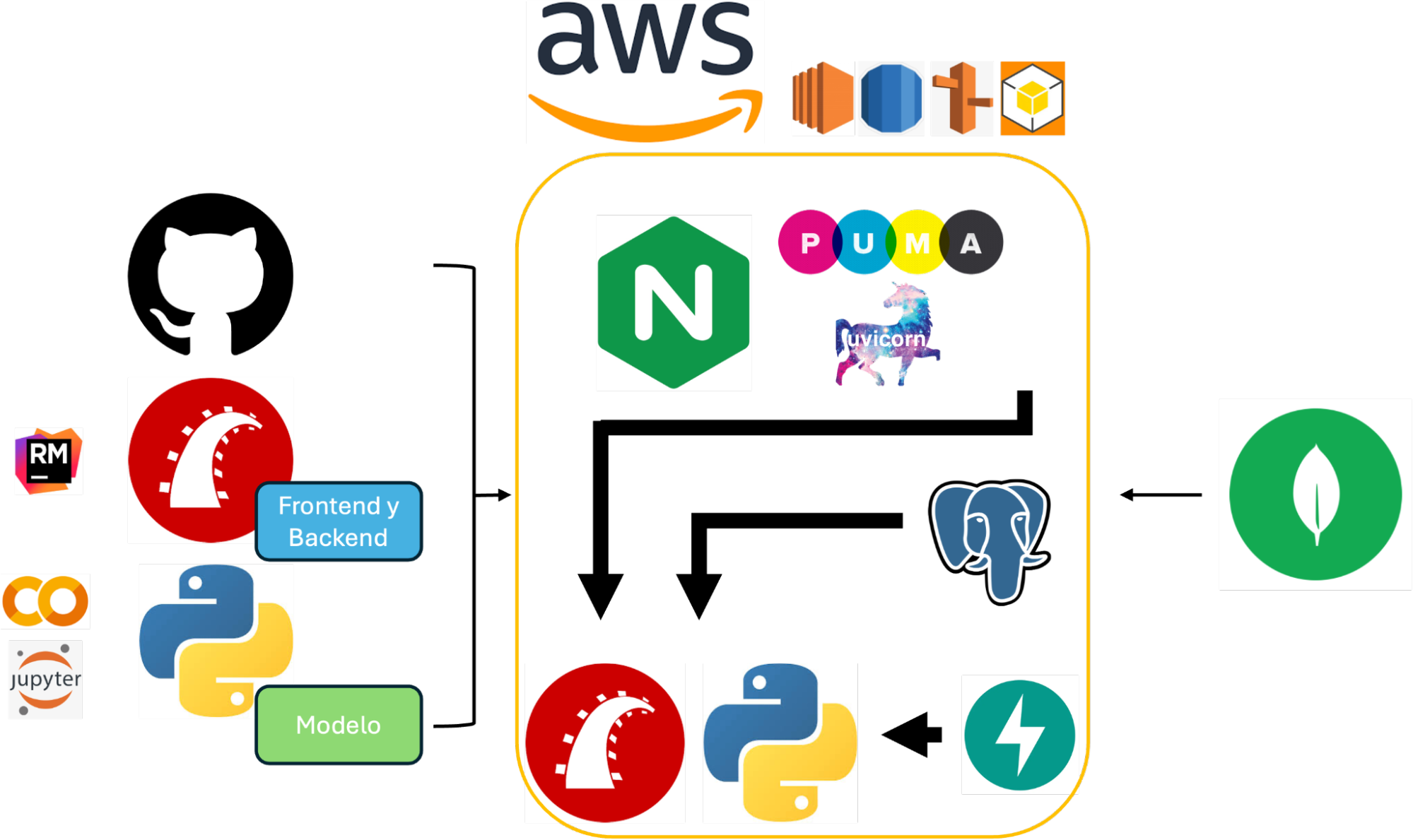
5.3.2.1. Arquitectura Full Stack: Interpretación y Aplicación
MongoDB
MongoDB es una base de datos NoSQL orientada a documentos que permite almacenar y consultar datos en formato JSON. Su flexibilidad y escalabilidad horizontal la hacen ideal para manejar grandes volúmenes de datos no estructurados, como los documentos financieros que forman la base del análisis en esta solución. Es especialmente útil para aplicaciones que requieren alta disponibilidad y rendimiento. Nosotros lo utilizamos porque el cliente ha almacenado información vital por años ahí.

Google Colab
Google Colaboratory (Colab) es un entorno de notebooks en la nube que permite ejecutar código Python sin necesidad de configuración local. Ofrece recursos de computación gratuitos (incluyendo GPU y TPU), lo que facilita la creación, prueba y entrenamiento de modelos de machine learning de manera colaborativa y rápida. Aquí codificamos nuestro modelo. Inherentemnte utilizamos Google drive de manera transparente para guardar nuestros resultados y avances.

Jupyter Notebooks
Jupyter Notebooks es una aplicación web que permite crear y compartir documentos con código en vivo, visualizaciones y texto explicativo. Es ampliamente utilizado en ciencia de datos y machine learning para documentar y ejecutar análisis de manera interactiva, siendo el soporte base en Colab para los notebooks de entrenamiento que hemos ejecutado.

Python
Python es un lenguaje de programación de alto nivel, versátil y ampliamente utilizado en el desarrollo de sistemas de inteligencia artificial. Su rica colección de librerías como NumPy, Pandas, Scikit-learn y TensorFlow facilita el procesamiento de datos, construcción de modelos y servicios backend como los implementados en nuestro proyecto FerMar.

FastAPI
FastAPI es un framework moderno y rápido para construir APIs con Python, basado en especificaciones OpenAPI. Permite desarrollar servicios REST eficientes y con validación automática, lo que se nos hace ideal para microservicios backend como el motor de consulta de documentos y predicciones en nuestra solución.

Ruby on Rails
Rails es un framework de desarrollo web escrito en Ruby, basado en la arquitectura MVC. Permite construir aplicaciones web robustas rápidamente, facilitando el manejo de base de datos, vistas y controladores. Lo utilizamos aquí como capa de frontend y backend principales, para nuestra plataforma WEB y API estructurada.

EC2 (Elastic Compute Cloud)
EC2 (Elastic Compute Cloud) es un servicio de AWS que permite ejecutar máquinas virtuales en la nube. En este proyecto, EC2 aloja todo el stack de la aplicación (FastAPI, Rails, NGINX y relacionados), lo que nos permite ofrecer al cliente alta disponibilidad, escalabilidad y control total del entorno de ejecución.

NGINX
NGINX es un servidor web y proxy inverso ligero, ideal para servir aplicaciones web y enrutar tráfico HTTP(s). En nuestra arquitectura, distribuye las solicitudes entrantes hacia Rails o FastAPI según las rutas configuradas y maneja certificados TLS para HTTPS.

Let's Encrypt (TLS/SSL) & AWS Route 53
Let's Encrypt es una autoridad certificadora que emite certificados SSL/TLS gratuitos. Lo hemos utilizado para habilitar HTTPS en la aplicación, garantizando la seguridad de las comunicaciones entre el cliente y los servidores backend. Nuestra URL es www.fmpredict.com/

PostgreSQL & AWS RDS
PostgreSQL es un sistema de gestión de bases de datos relacional y de código abierto. Es conocido por su fiabilidad, robustez y conformidad con estándares SQL. Nos sirvió como la base de datos principal en el entorno Rails, manejando datos estructurados con integridad transaccional.

Uvicorn
Uvicorn es un servidor ASGI (Asynchronous Server Gateway Interface) ligero para aplicaciones Python asincrónicas. Lo usamos para ejecutar FastAPI en producción, soportando concurrencia eficiente y alto rendimiento con bajo consumo de recursos.

Puma
Puma es un servidor web multihilo para aplicaciones Ruby/Rails. Soporta servidores con múltiples núcleos y es altamente eficiente para entornos de producción, gestionando el tráfico entrante a Rails mediante sockets Unix.

UFW (Uncomplicated Firewall) & AWS Security Groups
UFW es una herramienta de configuración de firewall simplificada para sistemas Linux. Nos permitió definir reglas de tráfico de red, aunque en este proyecto es secundario y redundante desde el punto de vista de ser utilizado como estrategia adicional de filtrado de requests desde el internet. Nosotros hemos utilizado como Firewall maestro a los grupos de seguridad de AWS.

GitHub
GitHub es una plataforma de control de versiones basada en Git, que permitió la colaboración entre Fer y Marc. En este proyecto, nos sirvió como repositorio central del código, facilitando la gestión del ciclo de vida del desarrollo y la integración continua.
